컨슈머 그룹
Categories:
개요
컨슈머 그룹은 여러 컨슈머가 하나의 토픽 파티션 집합을 분담해 처리할 수 있도록 묶어 주는 기본 단위입니다. 이 개념을 이해하면 컨슈머 수와 파티션 수의 관계, 장애 발생 시 재할당 흐름을 함께 이해할 수 있습니다.
핵심 내용
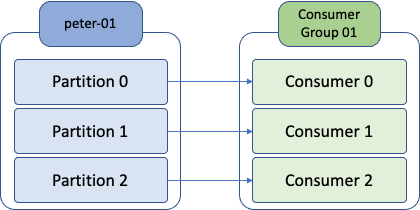
컨슈머는 컨슈머 그룹 안에 속한 것이 일반적인 구조로, 하나의 컨슈머 그룹 안에 여러 개의 컨슈머가 구성될 수 있음. 위 그림과 같이 토픽의 파티션과 일대일로 매핑되어 메시지를 가져오게 됨.
왼쪽에 peter-01이라는 토픽과 3개의 파티션으로 구성되어 있고, 오른쪽에는 consumer group 01이라는 컨슈머 그룹 아이디를 가진 컨슈머 그룹이 있으며, peter-01 토픽의 파티션 수와 동일한 3개의 컨슈머가 속해 있음.
컨슈머들은 하나의 컨슈머 그룹 안에 속해 있으며, 그룹 내의 컨슈머들은 서로의 정보를 공유 함.
예를 들어 Consumer01이 문제가 생겨 종료됐다면, Consumer02 또는 Consumer03은 Consumer01이 하던 일을 대신해 peter-01 토픽의 partition0을 컨슘하기 시작 함.
컨슈머 그룹을 이해할 때 가장 중요한 점은 “같은 그룹 안에서는 파티션이 분산 처리되고, 다른 그룹은 같은 메시지를 독립적으로 다시 읽을 수 있다"는 점입니다. 즉, 하나의 토픽을 두 개 이상의 서비스가 각자 소비해야 한다면 컨슈머 수를 늘리는 것이 아니라 별도의 컨슈머 그룹을 두는 식으로 모델링해야 합니다. 이 차이를 이해하지 못하면 처리 구조를 잘못 설계하기 쉽습니다.
또한 컨슈머 그룹은 장애 상황에서 자동 복구를 가능하게 하지만, 그 과정에서 리밸런싱 비용이 발생합니다. 컨슈머가 자주 재시작되거나 파티션 수 대비 컨슈머 구성이 불안정하면 리밸런싱이 반복되면서 실제 처리량과 지연 시간에 영향을 줄 수 있습니다. 그래서 운영 관점에서는 단순히 컨슈머 수를 늘리기보다 파티션 수, 그룹 구성, 인스턴스 안정성을 함께 봐야 합니다.
실무에서는 “컨슈머를 많이 붙이면 더 빨라진다"는 오해가 자주 생기지만, 실제로는 파티션 수가 처리 병렬성의 상한을 결정합니다. 예를 들어 파티션이 3개라면 같은 그룹 안에서 4번째 컨슈머는 대기 상태가 되며, 처리량을 높이지 못합니다. 따라서 컨슈머 그룹 설계는 파티션 수를 기준으로 잡고, 이후 장애 대응과 확장성을 함께 고려해 조정하는 접근이 필요합니다.
정리
컨슈머 그룹은 카프카의 병렬 처리와 장애 대응을 동시에 가능하게 만드는 핵심 개념입니다. 결국 파티션 수와 컨슈머 수의 관계를 적절히 설계하고, 장애 시 어떤 리밸런싱이 일어나는지 이해하는 것이 실무 운영의 기본입니다.