해당 카테고리는 Data Platform 관련된 기술 정보를 제공합니다.
1 - Apache Kafka
본 페이지는 Apache Kafka에 대해 공부한 내용을 제공합니다.
1.1 - 카프카 기본 개념과 구조
카프카의 기본 개념과 구조에 대해 기술하고 있습니다.
1.1.1 - 카프카 기초 다지기
카프카를 구성하는 주요 요소
- 주키퍼(Zookeeper) : 아파치 프로젝트 애플리케이션 이름으로 카프카의 메타데이터(metadata) 관리 및 브로커의 정상 상태 점검(health check)을 담당
- 카프카(Kafka) 또는 카프카 클러스터(Kafka cluster) : 아파치 프로젝트 애플리케이션 이름으로 여러 대의 브로커를 구성한 클러스터를 의미
- 브로커(Broker): 카프카 애플리케이션이 설치된 서버 또는 노드를 칭함
- 프로듀서(Producer) : 카프카로 메시지를 보내는 역할을 하는 클라이언트를 총칭
- 컨슈머(Consumer) : 카프카에서 메시지를 꺼내가는 역할을 하는 클라이언트 총칭
- 토픽(Topic) : 카프카는 메시지 피드들을 토픽으로 구분하고, 각 토픽의 이름은 카프카 내에서 고유 함.
- 파티션(Partition) : 병렬 처리 및 고성능을 얻기 위해 하나의 토픽을 여러 개로 나눈 것을 말함.
- 세그먼트(Segment) : 프로듀서가 전송한 실제 메시지가 브로커의 로컬 디스크에 저장되는 파일을 말함.
- 메시지(Message) 또는 레코드(Record) : 프로듀서가 브로커로 전송하거나 컨슈머가 읽어가는 데이터 조각을 말함.
리플리케이션(replication)
카프카에서 리플리케이션(replication)이란 각 메시지들을 여러 개로 복제해서 카프카 클러스터 내 브로커 들에 분산시키는 동작을 의미.
아래 그림은 peter-overview01 토픽을 리플리케이션 팩터 수 3으로 설정하여 각 브로커에 배치된 상태를 보여줌.

- 안정성을 목적으로 모든 토픽에 대해 각 3개의 리플리케이션으로 설정 할 수 있음.
- 리플리케이션 팩터수가 커지면 안정성은 높아지지만 그만큼 브로커 리소스를 많이 사용하게 됨.
- 복제에 대한 오버헤드를 줄여서 최대한 브로커를 효율적으로 사용하는 것을 권장
- 토픽 생성시 기준
- 테스트 개발 환경 : 리플리케이션 팩터 수를 1로 설정
- 운영 환경(로그성 메시지로서 약간의 유실 허용) : 리플레케이션 팩터 수를 2로 설정
- 운영 환경(유실 허용하지 않음) : 리플리케이션 팩터 수를 3으로 설정
- 안정성을 높이기 위해 리플리케이션 팩터 수를 4 이상 설정 할 수 있지만 경험상 3일 경우 충분히 메시지 안정성도 보장하고 적절한 디스크 공간을 사용할 수 있음.
- 리플리케이션 팩터 수를 4 이상으로 설정시 디스크 공간을 많이 사용하기 때문에 이 점을 염두해서 사용 할 것.
파티션(partition)
하나의 토픽이 한 번에 처리 할 수 있는 한계를 높이기 위해 토픽 하나를 여러 개로 나눠 병렬 처리가 가능하게 만든 것을 파티션(partition)이라고 함.
- 하나의 토픽을 여러 개로 나누면 분산 처리도 가능 함.
- 나뉜 파티션 수 만큼 컨슈머를 연결 할 수 있음.
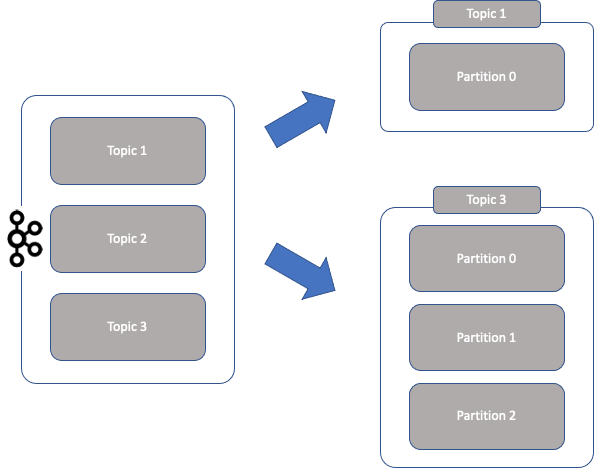
- 파티션 수도 토픽을 생성할 때 옵션으로 설정하게 되는데, 파티션 수를 정하는 기준은 다소 모호한 경우가 많음
- 파티션 수는 초기 생성 후 언제든지 늘릴 수 있지만, 반대로 한 번 늘린 파티션 수는 절대로 줄일 수 없음.
- 초기 파티션 수를 2 또는 4 정도로 생성 후, 메시지 처리량이나 컨슈머의 LAG등을 모니터링 하면서 조금씩 늘려가는 방법이 가장 좋음.
컨슈머 LAG이란?
운영 모니터링 지표 중 하나로 프로듀서가 보낸 메시지 수(카프카에 남아 있는 메시지 수) - 컨슈머가 가져간 메시지 수세그먼트(segment)
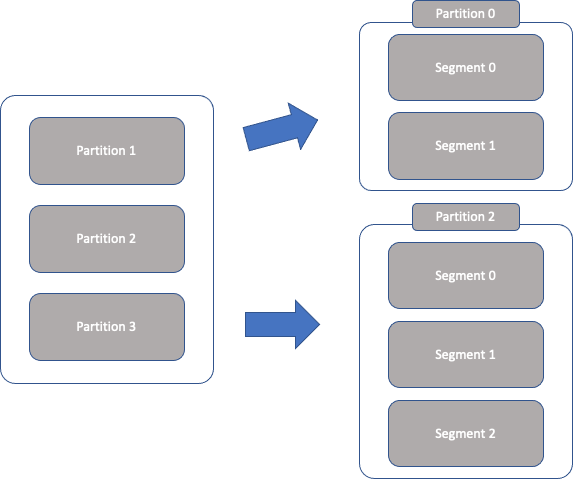
실제 메시지가 저장되는 파일 시스템 단위 프로듀서에 의해 브로커로 전송된 메시지는 토픽의 파티션에 저장되며, 각 메시지들은 세그먼트(segment)라는 로그 파일의 형태로 브로커의 로컬 디스크에 저장 됨.
카프카 처리 흐름
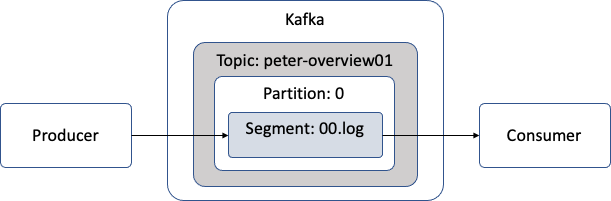
1.1.2 - 카프카의 핵심 개념
카프카가 높은 처리량과 안정성을 지니게 된 특성들에 대해 설명
주요 특징
1. 분산 시스템
카프카도 분산 시스템으로 유연한 리소스 확장 가능
2. 페이지 캐시
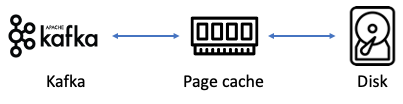
직접 디스크에 읽고 쓰는 대신 물리 메모리 중 애플리케이션이 사용하지 않는 일부 잔여 메모리를 활용하여 디스크 I/O에 대한 접근을 줄여 성능을 높일 수 있음
3. 배치 전송 처리
카프카는 프로듀서, 컨슈머 클라이언트들과 서로 통신하면서 수 많은 메시지를 주고 받음. 이 때 발생하는 많은 통신을 묶어서 처리 할 수 있다면, 단건으로 통신할 때에 비해 네트워크 오버헤드를 줄일 수 있음. 뿐만 아니라 장기적으로는 더욱 빠르고 효율적으로 처리 할 수 있음.
처리해야할 데이터 특성에 따라 실시간 또는 배치 작업으로 처리
- 상품 재고 수량 데이터 → 실시간 처리
- 구매 이력 정보 로그 → 배치 처리
4. 압축 전송
- 카프카는 메시지 전송 시 좀 더 성능이 높은 압축 전송을 사용하는 것을 권장하나 메시지의 형식이나 크기에 따라 또 다른 결과를 나타낼 수 있으니 실제로 메시지를 전송해보면서 압축 타입별로 테스트 후 결정을 추천
- 지원하는 압축 타입
- 높은 압축률 : gzip, zstd
- 빠른 응답 속도 : snappy, lz4
- 압축 전송 이점
- 네트워크 대역폭 및 회선 비용 절감
- 배치 전송과 결합해 사용할 경우 더욱 높은 효과를 얻을 수 있음
5. 토픽, 파티션, 오프셋
카프카는 토픽(topic)이라는 곳에 데이터를 저장하는데 메일 전송 시스템의 이메일 주소 정도의 개념으로 이해하면 됨.
토픽은 병렬 처리를 위해 여러개의 파티션이라는 단위로 나뉨
파티션의 메시지가 저장되는 위치를 오프셋이라고 부르며, 순차적으로 증가하는 숫자(64비트 정수) 형태
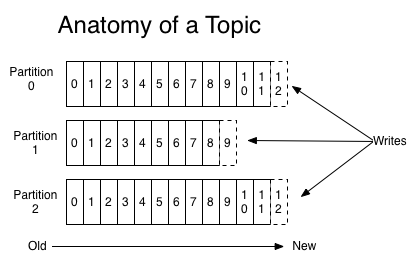
위 그림에서는 하나의 토픽이 3개의 파티션으로 나뉘며 프로듀스로부터 전송되는 메시지들의 쓰기 동작이 각 파티션별로 이뤄짐을 볼 수 있음.
각 파티션마다 순차적으로 증가하는 숫자들은 오프셋 임
각 파티션에서의 오프셋은 고유한 숫자로, 카프카에서는 오프셋을 통해 메시지의 순서를 보장하고 컨슈머에서는 마지막까지 읽은 위치를 알 수 있음.
6. 고가용성 보장
카프카는 분산 시스템이기 때문에 하나의 서버 또는 노드가 다운되어도 다른 서버 또는 노드가 장애가 발생한 서버의 역할을 대신해 안정적인 서비스 가능
이런 고가용성을 보장하기 위해 리플리케이션 기능을 제공
토픽 자체를 복제하는 것이 아니라 토픽의 파티션을 복제하는 것임
토픽을 생성할 때 옵션으로 리플리케이션 팩터 수를 지정할 수 있음
원본과 리플리케이션을 구분하기 위해 리더(leader)와 팔로워(follower)라고 구분을 함
- 리더(leader)는 프로듀서, 컨슈머로부터 오는 모든 읽기와 쓰기 요청을 처리
- 팔로워(follower)는 오직 리더로부터 리플리케이션
팔로워 수가 많을 수록 브로커의 디스크 공간도 소비되므로 이상적인 리플리케이션 팩터 수를 유지할 필요가 있으며 일반적으로 3으로 구성하도록 권장
7. 주키퍼의 의존성
주키퍼는 많은 분산 애플리케이션에서 코디네이터 역할을 하는 애플리케이션으로 사용 됨
여러 대의 서버를 앙상블(클러스터)로 구성하고, 살아 있는 노드 수가 과반수 이상 유지된다면 지속적인 서비스가 가능한 구조
즉, 주키퍼는 반드시 홀수로 구성해야 함
지노드(znode)를 이용해 카프카의 메타 정보가 주키퍼에 기록되며, 주키퍼는 이러한 지노드를 이용해 브로커의 노드 관리, 토픽 관리, 컨트롤러 관리 등을 수행
최근 카프카에서 주키퍼에 대한 의존성을 제거하려는 움직임이 진행 중임
- Apache Kafka 2.8 버전부터 주키퍼 대신 kraft 를 사용할 수 있으나 아직은 개발 단계로 문서에서도 표기 되어 있음
Note
KRaft is in early access and should be used in development only. It is not suitable for production.
1.1.3 - 프로듀서 기본 동작 및 주요 옵션
프로듀서 기본 동작과 주요 옵션에 대해 설명
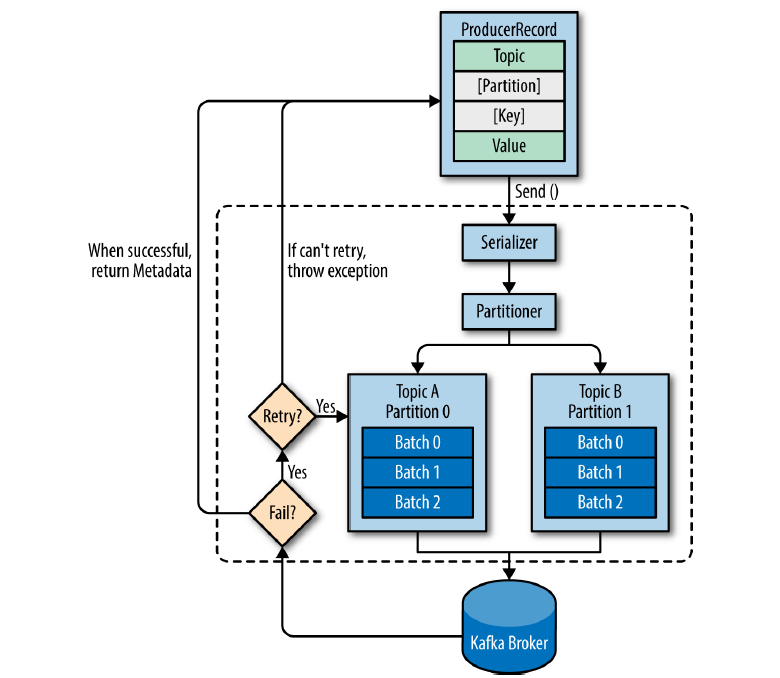
기본 동작
ProducerRecord라고 표시된 부분은 카프카로 전송하기 위한 실제 데이터이며, 레코드는 토픽, 파티션, 키, 밸류로 구성 됨.
프로듀서가 카프카로 레코드를 전송할 때, 카프카의 특정 토픽으로 메시지를 전송하기 때문에 레코드에서 토픽과 밸류(메시지 내용)는 필수 값이며, 특정 파티션을 지정하기 위한 레코드의 파티션과 특정 파티션에 레코드들을 정렬하기 위한 레코드의 키는 선택사항(옵션)
각 레코드들은 프로듀서의 send() 메소드를 통해 시리얼라이저(serializer), 파티셔너(partitioner)를 거침.
- 프로듀서 레코드의 파티션을 지정했을 경우
–> 파티셔너는 아무 동작하지 않고 지정된 파티션으로 레코드를 전달. - 프로듀서 레코드의 파티션을 지정 안했을 경우
–> 키를 가지고 파티션을 선택해 레코드를 전달 함. 기본적으로 라운드 로빈(round robin) 방식으로 동작.
send() 메소드 동작 이후 레코드들을 파티션별로 잠시 모아 둠. 모아둔 이유는 프로듀서가 카프카로 전송하기 전, 배치 전송하기 위함.
전송이 실패하면 재시도 동작이 이뤄지고, 지정된 횟수 만큼의 재시도가 실패하면 최종 실패 전달. 전송이 성공하면 메타데이터를 리턴하게 됨.
프로듀서 주요 옵션
| Producer Option | Description |
|---|---|
| bootstrap.servers | 카프카 클러스터는 클러스터 마스터라는 개념이 없으므로, 클러스터 내 모든 서버가 클라이언트의 요청을 받을 수 있음. 클라이언트가 카프카 클러스터에 처음 연결하기 위한 호스트와 포트정보를 나타 냄. |
| client.dns.lookup | 하나의 호스트에 여러 IP를 매핑해 사용하는 일부 환경에서 클라이언트가 하나의 IP와 연결하지 못할 경우에 다른 IP로 시도하는 설정. use_all_dns_ips가 기본값으로, DNS에 할당된 호스트의 모든 IP를 쿼리하고 저장. 첫 번째 IP로 접근 실패 시, 종료하지 않고 다음 IP로 접근 시도. resolve_canonical_bootstrap_servers_only 옵션은 Kerberos 환경에서 FQDN을 얻기 위한 용도로 사용 됨. |
| acks | 프로듀서가 카프카 토픽의 리더 측에 메시지를 전송한 후 요청을 완료하기를 결정하는 옵션. 0, 1, all(-1)로 표현하며, 0은 빠른 전송을 의미하지만, 일부 메시지 손실 가능성 있음. 1은 리더가 메시지를 받았는지 확인하지만, 모든 팔로워를 전부 확인하지 않음. 대부분 기본값으로 1을 사용. all은 팔로워가 메시지를 받았는지 여부 확인. 다소 느릴 수 있으나 하나의 팔로우가 있는 한 메시지 손실은 없음. |
| buffer.memory | 프로듀서가 카프카 서버로 데이터를 보내기 위해 잠시 대기(배치 전송이나 딜레이 등)할 수 있는 전체 메모리 바이트(byte) |
| compression.type | 프로듀서가 메시지 전송 시 선택할 수 있는 압축 타입. none, gzip, snappy, lz4, zstd 중 선택 |
| enbale.idempotence | 설정을 true로 하는 경우 중복 없는 전송이 가능하며, 이와 동시에 max.in.flight.requests.per.connection은 5 이하, retries는 0 이상, acks는 all로 설정해야 함. |
| max.in.flight.requests.per.connection | 하나의 커넥션에서 프로듀서가 최대한 ACK 없이 전송할 수 있는 요청 수. 메시지의 순서가 중요하다면 1로 설정할 것을 권장하지만 성능은 다소 떨어짐. |
| retries | 일시적인 오류로 인해 전송에 실패한 데이터를 다시 보내주는 횟수 |
| batch.size | 프로듀서는 동일한 파티션으로 보내는 여러 데이터를 함께 배치로 보내려고 시도. 적절한 배치 크기 설정은 성능에 도움을 줌. |
| linger.ms | 배치 형태의 메시지를 보내기 전 추가적인 메시지를 위해 기다리는 시간을 조정하고, 배치 크기에 도달하지 못한 상황에서 linger.ms 제한 시간에 도달 했을 때 메시지를 전송. |
| transactional.id | ‘정확히 한 번 전송’을 위해 사용하는 옵션. 동일한 TransactionalId에 한해 정확히 한 번을 보장. 옵션을 사용하기 전 enable.idempotence를 true로 설정해야 함. |
1.1.4 - 컨슈머 기본 동작 및 주요 옵션
컨슈머 기본 동작과 주요 옵션에 대해 설명
컨슈머는 카프카의 토픽에 저장되어 있는 메시지를 가져오는 역할을 담당. 단순하게 메시지만 가져오는 기능만 하는 것이 아니라 내부적으로는 컨슈머 그룹, 리밸런싱 등 여러 동작을 수행 함.
기본 동작
프로듀서가 카프카의 토픽으로 메시지를 전송하면 해당 메시지들은 브로커들의 로컬 디스크에 저장되며 컨슈머를 이용해 토픽에 저장된 메시지를 가져올 수 있음.
컨슈머 그룹은 하나 이상의 컨슈머들이 모여 있는 그룹을 의미하고, 컨슈머는 반드시 컨슈머 그룹에 속하게 됨. 그리고 컨슈머 그룹은 각 파티션의 리더에게 카프카 토픽에 저장된 메시지를 가져오기 위한 요청을 보냄.
이때 파티션 수와 컨슈머 수(하나의 컨슈머 그룹 안에 있는 컨슈머 수)는 1:1로 매핑되는 것이 이상적 임.
주의: 파티션 수와 컨슈머 수의 비율을 반드시 1:1로 매핑해야 하는 것은 아니지만, 파티션 수보다 더 많다고 해서 더 빠르게 토픽의 메시지를 가져오거나 처리량이 높아지는 것이 아니라 더 많은 수의 컨슈머들이 대기 상태로 존재하기 때문.
컨슈머 주요 옵션
| Consumer Option | Description |
|---|---|
| bootstrap.servers | 프로듀서와 동일하게 브로커의 정보를 입력. |
| fetch.min.bytes | 한 번에 가져올 수 있는 최소 데이터 크기. 지정한 크기보다 작은 경우, 요청에 응답하지 않고 데이터가 누적될 때까지 대기. |
| group.id | 컨슈머가 속한 컨슈머 그룹을 식별하는 식별자. 동일한 그룹 내의 컨슈머 정보는 모두 공유 됨. |
| heartbeat.interval.ms | 하트 비트가 있다는 것은 컨슈머의 상태가 active임을 의미. session.timeout.ms와 밀접한 관계가 있으며, session.timeout.ms보다 낮은 값으로 설정해야 함. 일반적으로 session.timeout.ms의 1/3로 설정. |
| max.partition.fetch.bytes | 파티션 당 가져올 수 있는 최대 크기 |
| session.timeout.ms | 이 옵션을 이용해, 컨슈머가 종료된 것인지를 판단. 컨슈머는 주기적으로 하트 비트를 보내야 하고, 만약 이 시간 전까지 하트 비트를 보내지 않았다면 해당 컨슈머는 종료된 것으로 간주하고 컨슈머 그룹에서 제외 후, 리밸런싱을 시작 함. |
| enable.auto.commit | 백그라운드로 주기적으로 오프셋을 커밋 |
| auto.offset.reset | 카프카에서 초기 오프셋이 없거나 현재 오프셋이 더 이상 존재하지 않는 경우에 다음 옵션으로 reset 함.
|
| fetch.max.bytes | 한 번의 가져오기 요청으로 가져올 수 있는 최대 크기 |
| group.instance.id | 컨슈머의 고유 식별자. 만약 설정한다면 static 멤버로 간주되어, 불필요한 리밸런싱을 하지 않음. |
| isolation.level | 트랜잭션 컨슈머에서 사용되는 옵션.
|
| max.poll.records | 한 번의 poll() 요청으로 가져오는 최대 메시지 수. |
| partition.assignment.strategy | 파티션 할당 전략.(Default : range) |
| fetch.max.wait.ms | fetch.min.bytes에 의해 설정된 데이터보다 적은 경우 요청에 대한 응답을 기다리는 최대 시간. |
1.1.5 - 컨슈머 그룹
컨슈머 그룹에 대해 설명
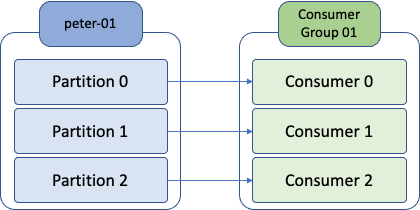
커슈머는 컨슈머 그룹안에 속한 것이 일반적인 구조로, 하나의 컨슈머 그룹 안에 여러 개의 컨슈머가 구성될 수 있음. 위 그림과 같이 토픽의 파티션과 일대일로 매핑되어 메시지를 가져오게 됨.
왼쪽에 peter-01이라는 토픽과 3개의 파티션으로 구성되어 있고, 오른쪽에는 consumer group 01이라는 컨슈머 그룹 아이디를 가진 컨슈머 그룹이 있으며, peter-01 토픽의 파티션 수와 동일한 3개의 컨슈머가 속해 있음.
컨슈머들은 하나의 컨슈머 그룹 안에 속해 있으며, 그룹 내의 컨슈머들은 서로의 정보를 공유 함.
예를 들어 Consumer01이 문제가 생겨 종료됐다면, Consumer02 또는 Consumer03은 Consumer01이 하던 일을 대신해 peter-01 토픽의 partition0을 컨슘하기 시작 함.
1.2 - 카프카 내부 동작 원리
카프카의 내부 동작 원리에 대해 기술하고 있습니다.
1.2.1 - 카프카 리플리케이션(Replication)
고가용성 분산 스트리밍 플랫폼인 카프카는 많은 데이터 파이프라인의 정중앙에 위치하는 메인 허브 역할을 하는데 만약 하드웨어의 문제나 점검 등으로 인해 정상적으로 동작하지 못해 전체 데이터 파이프라인에 영향을 미친다면 매우 큰 문제이다. 이러한 장애가 발생하더라도 중앙 데이터 허브로서 안정적인 서비스가 운영될 수 있도록 카프카 내부에서는 리플리케이션이라는 동작을 수행한다.
리플리케이션 동작 개요
카프카는 브로커의 장애에도 불구하고 연속적으로 안정적인 서비스 제공함으로써 데이터 유실을 방지하며 유연성을 제공한다. 카프카의 리플리케이션 동작을 위해 토픽 생성 시 필숫값으로 replication factor라는 옵션을 설정해야 함.
카프카는 해당 옵션을 이용해 관리자가 지정한 수만큼의 리플리케이션을 가질 수 있기 때문에 N개의 리플리케이션이 있는 경우 N - 1까지의 브로커 장애가 발생해도 메시지 손실 없이 안정적으로 메시지를 주고받을 수 있음.
리더와 팔로워
카프카는 내부적으로 모두 동일한 리플리케이션들을 리더와 팔로워로 구분하고, 각자의 역할을 분담시킨다.
리더는 리플리케이션 중 하나가 선정되며, 모든 읽기와 쓰기는 그 리더를 통해서만 가능하다. 프로듀서는 모든 리플리케이션에 메시지를 보내는 것이 아니라 리더에게만 메시지를 전송한다. 또한 컨슈머도 오직 리더로부터 메시지를 가져온다.
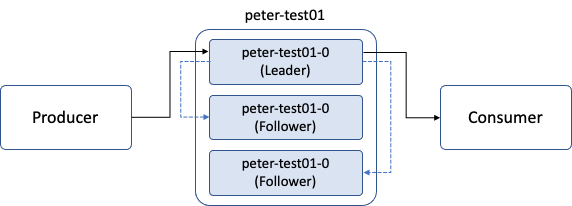
위 그림에서 peter-test01 토픽의 파티션 수는 1이고, 리플리케이션 팩터 수는 3을 나타낸다. 그림에서 처럼 토픽의 파티션 번호를 함께 표시하는데, peter-test01-0은 peter-test01 토픽의 0번 파티션이라는 뜻 임.
프로듀서는 peter-test01 토픽으로 메시지를 전송하는데, 파티션의 리더만 읽고 쓰기가 가능하므로 0번 파티션의 리더로 메시지를 보내며 컨슈머 동작에서도 역시 0번 파티션의 리더로부터 메시지를 가져온다.
리더만 읽고 쓰기 동작을 하므로 나머지 팔로워들은 리더에 문제가 발생하거나 이슈가 있을 경우를 대비해 언제든지 새로운 리더가 될 준비를 함. 따라서 컨슈머가 토픽의 메시지를 꺼내 가는 것과 비슷한 동작으로 지속적으로 파티션의 리더가 새로운 메시지를 받았는지 확인하고, 새로운 메시지가 있다면 해당 메시지를 리더로부터 복제를 수행.
복제 유지와 커밋
리더와 팔로워는 ISR(InSyncReplica)라는 논리적 그룹으로 묶여 있음. 이렇게 리더와 팔로워를 별도의 그룹으로 나누는 이유는 기본적으로 해당 그룹 안에 속한 팔로워들만이 새로운 리더의 자격을 가질 수 있기 때문. 즉, ISR 그룹에 속하지 못한 팔로워는 새로운 리더의 자격을 가질 수 없음.
ISR내의 팔로워들은 리더와의 데이터 일치를 유지하기 위해 지속적으로 리더의 테이터를 따라게가 되고, 리더는 ISR 내 모든 팔로워가 메시지를 받을 때까지 기다림. 하지만 팔로워가 네트워크 오류, 브로커 장애 등 이유로 리더로부터 리플리케이션하지 못하는 경우도 발생할 수 있음. 뒤처진 팔로워는 이미 리더와의 데이터가 불일치한 상태에 놓여 있기 때문에 만약 이 팔로워에게 새로운 리더를 넘겨준다면 데이터의 정합성이나 메시지 손실 등의 문제가 발생할 수 있음. 따라서 파티션의 리더는 팔로워들이 뒤처지지 않고 리플리케이션 동작을 잘하고 있는지 감사. 즉 리더에 뒤처지지 않고 잘 따라잡고 있는 팔로워들만이 ISR 그룹에 속하게 되며, 리더에 장애가 발생할 경우 새로운 리더의 자격을 얻을 수 있는 것임.
리더는 읽고 쓰는 동작은 물론, 팔로워가 리플리케이션 동작을 잘 수행하고 있는지도 판단 함. 만약 팔로워가 특정 주기의 시간만큼 복제 요청을 하지 않는다면, 리더는 해당 팔로워가 리플리케이션 동작에 문제가 발생했다고 판단해 ISR 그룹에서 추방 함.
Note
카프카 클러스터 운영 중 특정 토픽의 상태가 의심되거나 문제가 있다고 판단되면, 토픽 상세보기 명령을 통해 현재 ISR 상태를 점검해 봄으로써, 현재 토픽의 상태가 양호한지 불량한지 육안으로 확인 할 수 있음.
ISR 내에서 모든 팔로워의 복제가 완료되면, 리더는 내부적으로 커밋되었다는 표시를 하기 됨. 마지막 커밋 오프셋 위치는 **하이워터마크(high water mark)**라고 부름.
즉, 커밋되었다는 것은 리플리케이션 팩터 수의 모든 리플리케이션이 전부 메시지를 저장했음을 의미하며 커밋된 메시지만 컨슈머가 읽어갈 수 있음. 카프카에서 커밋되지 않은 메시지를 컨슈머가 읽을 수 없게 하는 이유는 바로 메시지의 일관성을 유지하기 위함.
모든 브로커는 재시작될 때, 커밋된 메시지를 유지하기 위해 로컬 디스크의 **‘replication-offset-checkpoint’**라는 파일에 마지막 커밋 오프셋 위치를 저장.
‘replication-offset-checkpoint’ 파일은 브로커 설정 파일에서 설정한 로그 디렉토리 경로에 있으며, 브로커 설정 파일의 로그 디렉토리는 /data/kafka-logs로 설정되어 있으므로, 해당 디렉토리 하위에 위치.
🛠 만약 특정 토픽 또는 파티션에 복제가 되지 않거나 문제가 있다고 판단되는 경우, ‘replication-offset-checkpoint’ 라는 파일의 내용을 확인하고 리플리케이션되고 있는 다른 브로커들과 비교해 살펴보면, 어떤 브로커, 토픽, 파티션에 문제가 있는지 파악 할 수 있음.
2 - Apache Spark
본 페이지는 Apache Spark에 대해 공부한 내용을 제공합니다.
2.1 - Tips
본 페이지는 Apache Spark 관련 Tip에 대해 정리한 내용을 제공합니다.
2.1.1 - DataFrame에서 Column 유무 체크 방법
DataFrame에서 Column 체크하는 방법을 설명합니다.
DafaFrame에서 Column 유무 검사
// Example 1
val schema = StructType( Array(
StructField("language", StringType,true),
StructField("users", IntegerType,true)
))
val rowData= Seq(Row("Java", 20000),
Row("Python", 100000),
Row("Scala", 3000))
var df = spark.createDataFrame(rowData,schema)
df.printSchema()
// root
// |-- language: string (nullable = true)
// |-- users: integer (nullable = true)
Spark DataFrame의 columns attribute는 모든 column 이름을 Array[String] 타입으로 반환합니다. Column의 유무를 check하기 위해 contains() 함수를 이용해서 column의 유무를 확인 할 수 있습니다.
val columnName = "users"
if(df.columns.contains(columnName))
println("column exists")
else
println("column not exists")
중첩된 구조의 DataFrame에서 Column 유무 검사
// Example2
[{
"manufacturer": "hyundai",
"model":[
{
"name" : "2022 Genesis GV70 ",
"release-date" : "2021. 12. 8",
"price" : "6,000"
},
{
"name" : "2022 Genesis G90 ",
"release-date" : "2021. 12. 19",
"price" : "9,300"
}
]
},
{
"manufacturer": "bmw",
"model":[
{
"name" : "2023 i7 ",
"release-date" : "-",
"price" : "-"
},
{
"name" : "2023 x5 ",
"release-date" : "2022",
"price" : "12,420"
}
]
},
{
"manufacturer": "benz",
"model":[
{
"name" : "2022 AMG GT 4-door coupe ",
"release-date" : "2022. 3. 25",
"price" : "16,960"
},
{
"name" : "2022 C Class ",
"release-date" : "2022. 4. 01",
"price" : "6,800"
}
]
}]
위와 같은 중첩된 구조의 Json 형식의 데이터를 DataFrame으로 구성했을 경우 Column의 유무를 검색하는 방법을 알아봅니다.
val jsonStr =
"""
|[{
| "manufacturer": "hyundai",
| "model":[
| {
| "name" : "2022 Genesis GV70 ",
| "release-date" : "2021. 12. 8",
| "price" : "6,000"
| },
| {
| "name" : "2022 Genesis G90 ",
| "release-date" : "2021. 12. 19",
| "price" : "9,300"
| }
| ]
|},
|{
| "manufacturer": "bmw",
| "model":[
| {
| "name" : "2023 i7 ",
| "release-date" : "-",
| "price" : "-"
| },
| {
| "name" : "2023 x5 ",
| "release-date" : "2022",
| "price" : "12,420"
| }
|
| ]
|},
|{
| "manufacturer": "benz",
| "model":[
| {
| "name" : "2022 AMG GT 4-door coupe ",
| "release-date" : "2022. 3. 25",
| "price" : "16,960"
| },
| {
| "name" : "2022 C Class ",
| "release-date" : "2022. 4. 01",
| "price" : "6,800"
| }
|
| ]
|}]
|""".stripMargin
val df = sqlContext.read.json(Seq(jsonStr).toDS())
df.printSchema()
df.show(false)
root
|-- manufacturer: string (nullable = true)
|-- model: array (nullable = true)
| |-- element: struct (containsNull = true)
| | |-- name: string (nullable = true)
| | |-- price: string (nullable = true)
| | |-- release-date: string (nullable = true)
+------------+---------------------------------------------------------------------------------------+
|manufacturer|model |
+------------+---------------------------------------------------------------------------------------+
|hyundai |[[2022 Genesis GV70 , 6,000, 2021. 12. 8], [2022 Genesis G90 , 9,300, 2021. 12. 19]] |
|bmw |[[2023 i7 , -, -], [2023 x5 , 12,420, 2022]] |
|benz |[[2022 AMG GT 4-door coupe , 16,960, 2022. 3. 25], [2022 C Class , 6,800, 2022. 4. 01]]|
+------------+---------------------------------------------------------------------------------------+
df.columns은 중첩된 구조에서 내부 컬럼을 반환하지 않습니다. 그렇기 때문에 DataFrame이 중첩된 구조를 가질 경우 df.schema.simpleString()을 이용하여 중첩 구조의 스키마 컬럼을 검사할 수 있습니다.
df.columns
// Array[String] = Array(manufacturer, model)
df.schema.simpleString()
// String = struct<manufacturer:string,model:array<struct<name:string,price:string,release-date:string>>>
df.schema.simpleString.contains("release-date:")
// true
DataFrame에서 Field 유무 검사
동일한 데이터 유형을 가진 열이 있는지 확인하려면 스파크 스키마 함수 df.schema.fieldNames 또는 df.schema.contain() 함수를 사용합니다.
import org.apache.spark.sql.types.{StringType, StructField}
df.schema.fieldNames.contains("manufacturer")
df.schema.contains(StructField("manufacturer",StringType,true))
2.1.2 - Dataframe 에서 그룹 별 첫 번째 행 추출하는 방법
데이터 프레임에서 그룹별 첫 번째 행 추출하는 방법을 설명합니다.
SparkSQL의 window 함수를 이용해 DataFrame 에서 각 그룹별 최상위 행을 추출하는 방법을 설명합니다.
테스트 셋 준비
val testData = Seq(
("Nike Dunk Low Retro Black", "Nike", "179,000"),
("Nike x Off-White Air Force 1 Mid SP White", "Nike", "234,000"),
("Nike Air Force 1 '07 Low White", "Nike", "127,000"),
("Nike Dunk Low Retro Valerian Blue", "Nike", "166,000"),
("Adidas Yeezy Foam RNNR Onyx", "Adidas", "190,000"),
("Adidas Yeezy Foam RNNR Stone Sage", "Adidas", "197,000"),
("Adidas Yeezy Boost 350 V2 Onyx", "Adidas", "322,000"),
("Adidas Yeezy Slide Pure - Re-Release Ver.", "Adidas", "161,000"),
("Puma x Maison Kitsune Roma White", "Puma", "200,000"),
("Puma x Rick and Morty MB.01 Jasmine Green Energy Rose", "Puma", "319,000"),
("Puma x Ader Error Vaderon White", "Puma", "277,000")
)
import spark.implicits._
val df = testData.toDF("model", "brand", "price")
df.show()
// +--------------------+------+-------+
// | model| brand| price|
// +--------------------+------+-------+
// |Nike Dunk Low Ret...| Nike|179,000|
// |Nike x Off-White ...| Nike|234,000|
// |Nike Air Force 1 ...| Nike|127,000|
// |Nike Dunk Low Ret...| Nike|166,000|
// |Adidas Yeezy Foam...|Adidas|190,000|
// |Adidas Yeezy Foam...|Adidas|197,000|
// |Adidas Yeezy Boos...|Adidas|322,000|
// |Adidas Yeezy Slid...|Adidas|161,000|
// |Puma x Maison Kit...| Puma|200,000|
// |Puma x Rick and M...| Puma|319,000|
// |Puma x Ader Error...| Puma|277,000|
// +--------------------+------+-------+
위 테스트 셋은 스포츠웨어 브랜드의 모델별 가격을 정리한 데이터 셋으로 각 브랜드 별 최고 모델에 대해 추출해 봅니다.
‘brand’ 그룹 별 ‘price’ 가 가장 높은 행 추출
import org.apache.spark.sql.expressions.Window
val window = Window.partitionBy("brand").orderBy(col("price").desc)
val extractedDF = df.withColumn("row", row_number.over(window)).
where(col("row").equalTo(1)).drop("row")
extractedDF.show()
// +--------------------+------+-------+
// | model| brand| price|
// +--------------------+------+-------+
// |Nike x Off-White ...| Nike|234,000|
// |Puma x Rick and M...| Puma|319,000|
// |Adidas Yeezy Boos...|Adidas|322,000|
// +--------------------+------+-------+
먼저 ‘brand’ 그룹을 지정하고 ‘price’ 컬럼에 대해 오름차순으로 정리하는 windowSpec을 생성합니다. DataFrame에서 window 함수인 row_number를 이용하여 새로운 컬럼 ‘row’를 추가합니다. where 조건을 통해 ‘row’ == 1 조건의 행만 추출한 후, “row” 컬럼을 삭제합니다.